| 音频降噪之人声分离 | 您所在的位置:网站首页 › ultimate vocal remover怎么用 › 音频降噪之人声分离 |
音频降噪之人声分离
|
音频降噪
Ultimate Vocal Remover GUI v5.5.1工具使用
1:是什么
集成目前最先进的从音频文件中分离人声的源分离模型。 本工程,将Ultimate Vocal Remover GUI v5.5.1界面工具,改写成可以在服务器端批量推理的工具。 界面仓库地址:https://github.com/Anjok07/ultimatevocalremovergui 2: 有哪些功能暂不支持两种模型联合处理。 (1)VR Architecture:具有9种模式的模型,这些模型使用幅度谱图进行信源分离(VR是索尼的AI算法) 1)1_HP-UVR.pth:针对乐器伴奏的模型,1,效果比2_HP-UVR还差一点 2)2_HP-UVR.pth:上个模型微调版本,1,人声分离效果没有3_HP-Vocal-UVR好 3)3_HP-Vocal-UVR.pth:强化人声提取,1,还可以,但是重点噪音的地方,存在把主要人声也去掉的现象 4)4_HP-Vocal-UVR.pth:上一个模型微调版,比上一个版本更激进,1,跟3_HP-Vocal-UVR差不太多 5)5_HP-Karaoke-UVR.pth:分离主要人声,能够去掉背景人声 ,1,效果一般 6)6_HP-Karaoke-UVR.pth: 分离主要人声,能够去掉背景人声 7)7_HP2-UVR.pth: 使用更多数据集和新参数训练出的更强大的乐器模型 8)8_HP2-UVR.pth:上一个模型微调版 9)9_HP2-UVR.pth:上一个模型微调版 (2)MDX-Net:具有5种模式的模型,这些模型使用混合频谱/波形进行源分离(处理高音质音频的AI算法,对人声的识别提取能力强大,就是慢一些) 1)UVR_MDXNET_1_9703.onnx:在SDR上得分9.703 ,1,效果没有VR Architecture或者Demucsv4好 2)UVR_MDXNET_2_9682.onnx:在SDR上得分9.682 3)UVR_MDXNET_3_9662.onnx:在SDR上得分9.662 4)UVR_MDXNET_KARA.onnx:分离主要人声,保留背景人声,1,不知是否参数设置有问题,效果很差 5)UVR_MDXNET_main.onnx:MDX-Net最强也是最耗资源的模型 (3)Demucs:支持v1-v4:这些模型使用混合频谱/波形进行源分离(Demucs是Facebook开源的声音分离模型,可以分离人声和乐器) 1) v4 | hdemucs_mmi :1,混合 Demucs v3模型重新训练 2)v4 | htdemucs ;1,v4第一个默认版本 3) v4 | htdemucs_ft :1, htdemucs微调版本,分离将花费4倍的时间 但可能会好一点。与第一个版本相同的训练集。 4) v4 | htdemucs_6s : 1 ,6 个轨道版本,对人声剥离的比较干净,感觉人声分离的最清晰 5) v4 | UVR_Model_ht 6) v3 | UVR_Model_Bag 7) v3 | UVR_Model_2 8) v3 | UVR_Model_1 9) v3 | repro_mdx_a_time 10) v3 | repro_mdx_a_hybrid 11) v3 | repro_mdx_a 12) v3 | mdx_q 13) v3 | mdx_extra_q 14) v3 | mdx_extra:1 15) v3 | mdx :1 ,之前比赛里的第1名,最高质量的模型 官网仓库地址:https://github.com/facebookresearch/demucs 网络结构: double U-Net encoder/decoder structure。 0, 下载源界面仓库工程,地址:https://github.com/Anjok07/ultimatevocalremovergui 脚本仓库地址:https://download.csdn.net/download/jiafeier_555/88085675?spm=1001.2014.3001.5501 将脚本仓库地址脚本添加到源界面仓库工程,按源界面仓库工程要求配置环境,即可跑通。 1,配置参数 inputPaths: "./wav" #音频文件夹 export_path: "./wav_result" #人声分离后的结果保存 chosen_process_method_var: "MDX-Net" # MDX-Net,Demucs,VR Architecture,Ensemble Mode demucs_model_var: htdemucs_6s #v4 | UVR_Model_ht,v4 | htdemucs_6s,v4 | htdemucs_ft,v4 | htdemucs,v4 | hdemucs_mmi mdx_net_model_var: UVR_MDXNET_KARA #UVR_MDXNET_1_9703,UVR_MDXNET_KARA vr_model_var: 3_HP-Vocal-UVR #5_HP-Karaoke-UVR,4_HP-Vocal-UVR ,3_HP-Vocal-UVR,2_HP-UVR,1_HP-UVR is_primary_stem_only_var: True #True:表示只输出人声音频 aggression_setting: 4 #VR Architecture算法模式下,除燥的强度2,运行脚本 python infer.py |
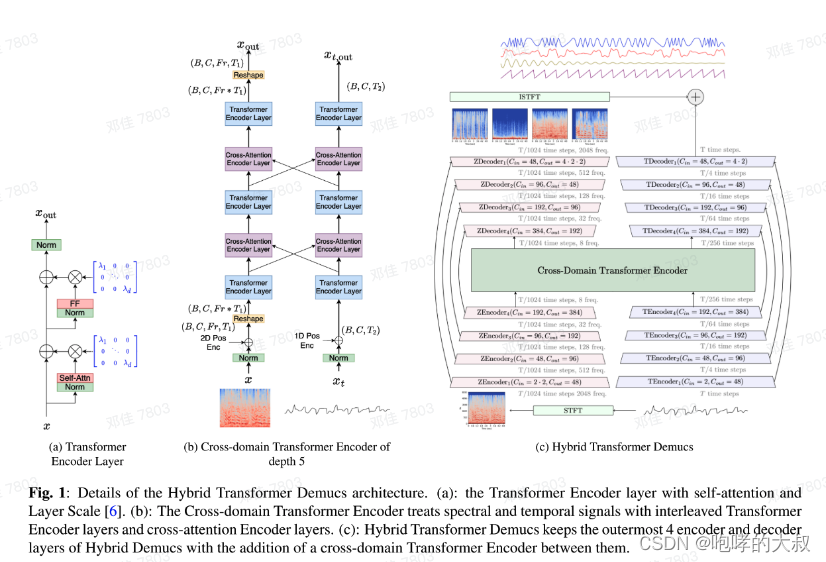 一个轨道一个模型,除了htdemucs_6s,其他,比如htdemucs与htdemucs_ft等,均4个音轨道,分别[“drums”,“bass”,“other”,“vocals”],每个模型结构一样,输入一段音频频谱,输出一段对应音轨的音频频谱。htdemucs_6s包含6个音轨道模型,分别为[“drums”,“bass”,“other”,“vocals”,“guitar”,“piano”] 滑窗:
一个轨道一个模型,除了htdemucs_6s,其他,比如htdemucs与htdemucs_ft等,均4个音轨道,分别[“drums”,“bass”,“other”,“vocals”],每个模型结构一样,输入一段音频频谱,输出一段对应音轨的音频频谱。htdemucs_6s包含6个音轨道模型,分别为[“drums”,“bass”,“other”,“vocals”,“guitar”,“piano”] 滑窗:【本文地址】